

Duplicate Content – Definition
Der Begriff Duplicate Content (zu Deutsch ,,doppelte Inhalte’’ oder ,,duplizierte Inhalte’’) meint, dass identische Texte oder Textpassagen unter verschiedenen URLs vorzufinden sind. Zum einen kann es sich dabei um einen Textblock handeln, der auf der eigenen sowie einer externen Website vorkommt. Zum anderen kann auch eine einzelne Unterseite gemeint sein, die über mehrere URLs erreichbar ist.
Duplicate Content stellt folglich das Gegenteil von einzigartigem, also Unique Content dar. Suchmaschinen wie Google sind in der Lage, duplizierte Inhalte im Index zu erkennen und herauszufiltern – und bei Bedarf auch abzustrafen.
Verschiedene Arten kopierter Inhalte
Wie im vorherigen Absatz angeschnitten, gibt es verschiedene Arten von Duplicate Content – auch innerhalb einer Domain. Welche das sind, erfährst Du jetzt:
Interner Duplicate Content
Damit sind all jene Inhalte gemeint, die zu einem Webauftritt gehören, jedoch über unterschiedliche URLs erreichbar sind (z.B. mit http:// UND mit https://). Diese Art von Duplicate Content ist meist nicht vorsätzlich entstanden, sondern durch Fehler bei der Websiteplanung begründet. Oder aber derselbe Content-Block wird für verschiedene Bereiche eines Webauftrittes angezeigt, weil es sich z.B. um Informationen über das Unternehmen handelt. Gibt es auf Deiner Webseite einzelne Pages, die sich ähneln oder gleichen, kann sich Google oftmals nicht entscheiden, welcher Inhalt der Relevanteste ist. Deshalb indexiert Google dann oft alle Versionen und Du hast Duplicate Content im Index der Suchmaschine. Eine Abstrafung gibt es hierbei zwar nicht, jedoch ,,konkurrieren’’ die Seiten miteinander, was im Sinne der Suchmaschinenoptimierung nicht förderlich ist. Du generierst höchstwahrscheinlich mit jeder Seite wenig Klicks, statt mit einer einzigen Seite zahlreiche Nutzer zu locken.
Externer Duplicate Content
Dabei handelt es sich um Textpassagen, die auf zwei komplett verschiedenen Websites/Domains aufrufbar sind, zum Beispiel auf einem Gartenbau-Onlineshop sowie auf einem Blog für Hobbygärtner. Hier liegt die Annahme nahe, dass eine der Seiten den Text der anderen Page bewusst übernommen hat. Google erkennt den Duplicate Content hier als Täuschungsversuch und leitet Gegenmaßnahmen ein, wie z.B. Abstrafung durch Rankingverlust.
Near Duplicate Content
Near Duplicate Content bezeichnet Inhalte, die sich sehr ähneln, da Textbausteine entweder nur ganz leicht umgeschrieben wurden oder aber kopiert und mit anderen Boilerplate-Elementen (z.B. Footer) versehen sind.
Ursachen für Duplicate Content
Mögliche Gründe Duplicate Content sind:
- Der Inhalt wird unbeabsichtigt auf anderen Domains und Subdomains der Seite angezeigt (mit und ohne “www“ oder mit http:// UND mit https://).
- Die Abwesenheit von Trailing Slashes, also Slashes am Ende einer URL.
- Derselbe Content-Block wird für verschiedene Bereiche einer Webseite angezeigt, da es sich z.B. um Informationen über das Unternehmen handelt oder ähnliche Produktbeschreibungen in einem Online-Shop.
- Seiten mit gleichem Content, die für mobile Geräte und als Desktop-Ansicht angeboten werden.
- Der Content kann keiner klaren URL durch das Content Management System zugewiesen werden.
- Verwendung identischer Produktbeschreibungen bei verschiedenen Online-Shops.
- Eine Webseite übersetzt ihre Inhalte in andere Sprachen.
Genaueres zu den genannten Ursachen erfährst Du in diesem Video:
Sie sehen gerade einen Platzhalterinhalt von Youtube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenBei Duplicate Content handelt es sich nicht immer um einen vorsätzlichen Täuschungsversuch. Die meisten doppelten Inhalte sind der Kategorie interner Duplicate Content zuzuordnen, die auf Fehler bei der Konfiguration des Servers oder auf falsche Planung von Webseiten zurückzuführen sind.
Warum stellt Duplicate Content ein Problem dar?
Gleiche Textpassagen auf verschiedenen themenbezogenen Webseiten sind nicht nur für Nutzer irritierend. Auch den Suchmaschinen missfällt Duplicate Content erheblich.
Doppelt vorkommende Inhalte sind in vielen Fällen absichtliche Plagiate. Das ist eine Form von Betrug und dementsprechend natürlich nicht Google-richtlinienkonform. Deshalb wirkt sich kopierter Content negativ auf die eigene Platzierung in den SERPs aus.
Außerdem verstoßen beabsichtigte Kopien gegen das Urheberrecht. Der Betroffene kann die kopierte Webseite kontaktieren und sie dazu aufzufordern, die Originalquelle anzugeben oder sogar den duplizierten Inhalt dauerhaft zu löschen. Niemand freut sich darüber, wenn die eigene Arbeit kopiert wird. Denn oftmals haben die Texter und Webseitenbetreiber sehr viele Stunden darin investiert, das passende Thema zu recherchieren und daraus relevanten Content mit Mehrwert zu erstellen.
Die Suchmaschine identifiziert den kopierten Content (also den jüngsten Inhalt) und entfernt ihn aus den Top-Ergebnissen im Suchmaschinenindex, sodass die Website der Originalquelle im Ranking besser zu finden ist.

Screenshot: Google hat Duplicate Content aus SERPs entfernt
Für die Suchmaschinenoptimierung stellt Duplicate Content daher ein großes Problem dar und sollte weitestgehend vermieden werden.
So erkennen Suchmaschinen Duplicate Content
Suchmaschinen wie Google und Bing identifizieren Duplicate Content mithilfe ihres Algorithmus. Wie genau das funktioniert, ist nicht bekannt. Man geht jedoch davon aus, dass sie Sätze aus Webtexten in einzelne sogenannte ,,Shingles’’ unterteilen und vergleichen. Bei Shingles handelt es sich um Wortgruppen innerhalb eines Satzes, die aus jeweils 3 Wörtern bestehen.
Nehmen wir als Beispiel den Satz „Trendige Taschen für Damen in Schwarz.“ wie er in einem Online-Shop vorkommen könnte. Dieser Satz lässt sich in folgende Shingles unterteilen: „Trendige Taschen für“, „Taschen für Damen“, „für Damen in“, „Damen in Schwarz“.
Nun stellen wir den ähnlichen Satz „Stylische Taschen für Damen in Braun.“ dem Vorherigen gegenüber. Auch hier lässt sich eine Unterteilung in vier Shingles vornehmen: „Stylische Taschen für“, „Taschen für Damen“ und „für Damen in“ sowie „Damen in Braun“.
Beim Vergleich beider Sätze wird klar, dass zwei der vier Shingles identisch sind, und zwar: „Taschen für Damen“ und „für Damen in“. Da sich die Sätze in jeweils 4 Shingles unterteilen ließen, rechnet man die zwei identischen Shingles durch die Gesamtanzahl von vier Shingles pro Satz und erhält das Ergebnis 2. Das bedeutet, dass beide Sätze textlich zu 50% übereinstimmen. Die Suchmaschinen gehen im gesamten Text nach diesem Schema vor und erarbeiten dadurch zu wie viel Prozent sich zwei Inhalte gleichen. Ab 25 % identischem Content kann es für die Webseitenbetreiber des jüngsten (also kopierten) Inhalts kritisch werden.
Was Du ruhig verwenden kannst
Von Duplicate Content wird nicht gesprochen, wenn ein kurzer Vorspann und eine Überschrift von Beiträgen auf einer Übersichtsseite zum Anteasern verwendet werden. Solltest Du daher bei Deiner Internetrecherche auf gute Headlines treffen, kannst Du diese auch für Deine Beiträge verwenden, sofern Sie zum Inhalt passen.
Wörtliche oder ähnliche Zitate, die nur gelegentlich in einem Text vorkommen, stellen ebenso keine Gefahr dar. Am besten kennzeichnest Du diese mit Gänsefüßchen und einer Urheber-Angabe.
Auch kannst Du einzelne Absätze kopieren, solange Du mehr Unique Content in Deinem Beitrag lieferst. Über 80 % des Textes sollten am besten aus Deiner eigenen Feder stammen.
So prüfst Du Duplicate Content
Es gibt verschiedene Tools und Add-ons, die Deine Texte mit anderen Webressourcen vergleichen und doppelte Textpassagen anzeigen.
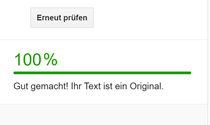
Textprüfung von Semrush zeigt wie viel Prozent des Textes Unique Content ist
Neben kostenpflichtiger Software mit Zusatzfunktionen gibt es auch einfache Online-Tools, welche Deinen Text kostenfrei auf Duplicate Content prüfen. Auch für CMS wie WordPress gibt es Duplicate Content Checks, die Du bei diversen Plug-ins nutzen kannst. Durchstöbere das Internet nach dem passenden Programm für Dich, um Duplicate Content zu finden, bevor Deine Inhalte online gehen!
Duplicate Content vermeiden
Interner Duplicate Content wird meist nicht abgestraft und lässt sich mit einer Reihe an Handgriffen lösen, wie z.B. Canonical Tags oder Weiterleitungen. Doch wie sieht es aus redaktioneller Sicht aus? Die einzige Möglichkeit, um Duplicate Content zu vermeiden, ist es, von vornherein auf Unique Content zu setzen. Nutze bei Deiner Recherche möglichst viele Quellen, um einen großen Pool an Informationen und Formulierungen zu haben, aus denen Du Deinen Text erstellen kannst. Plane für das Schreiben genügend Zeit ein, damit Du alle Informationen in Deinen eigenen Worten umwandeln kannst. Im Internet gibt es zahlreiche Tools, die Dir dabei helfen, Synonyme für verschiedene Begriffe zu finden. Die Verwendung dieser Synonyme setzt oftmals einen abweichend grammatikalischen Aufbau des Satzes voraus, sodass sich wiederholende Shingles gut vermeiden lassen.
Eine bessere Alternative wäre es, die Texte von professionellen Online Redakteuren verfassen zu lassen. Webtexter achten besonders darauf, aus verschiedenen Quellen einen einzigartigen Webseitencontent zu kreieren. Das eignet sich besonders für Unternehmen, die über keine eigene Redaktion verfügen oder die Kapazitäten der Texter bereits ausgelastet ist.
Duplicate Content – Unser Fazit
Schreibe nicht von anderen Websites ab und veröffentliche keine identischen Texte mehrfach auf Deiner Website (doppelte Produkttexte etc.). Sollte das doch mal der Fall sein, zeichne doppelte Inhalte technisch entsprechend aus, z.B. mit einem Canonical-Tag. Diverse Tools und Add-ons können Dir dabei helfen, Duplicate Content zu vermeiden oder Deinen Webauftritt regelmäßig auf Plagiate zu scannen. So gefährdest Du Deine Rankings auf Google und Co. nicht.
© OpturaDesign – stock.adobe.com




Seien Sie der Erste und schreiben Sie uns Ihre Gedanken zu diesem Beitrag. Wir freuen uns über Ihre Anregungen, Lob und Tadel gleichermaßen.